
welcome to me blog one’s again
pada kesempatan kali ini saya ingin share mengenai tugas saya
artificial Intelegence mengenai Learning by Example
1. Apa yang dimaksud supervised learning, unsupervised learning dan reinforcement learning?
– Supervised learning : merupakan suatu pembelajaran yang terawasi dimana jika output yang diharapkan telah diketahui sebelumnya. Biasanya pembelajaran ini dilakukan dengan menggunakan data yang telah ada.
Atau
teknik pembelajaran mesin dengan membuat suatu fungsi dari data latihan. Data latihan terdiri dari pasangan nilai input dan output yang diharapkan dari input yang bersangkutan. Tugas dari Supervised learning adalah untuk memprediksi nilai fungsi untuk nilai semua input yang ada.
Contoh :
– Sebagai contoh ada data luas rumah (x) dan harga (y). lalu dimasukkan dalam grafik x dan y-nya. Dimana setelah itu dibuat regresi antara x dan y-nya. Setelah membuat regresi dapat dipastikan kita dapat memprediksi dari hasil regresi harga rumah dengan luas tertentu.
– Contoh algoritma jaringan saraf tiruan yang mernggunakan metode supervised learning adalah hebbian (hebb rule), perceptron, adaline, boltzman, hapfield, dan backpropagation.
– Misalnya sebuah program diberikan benda berupa bangku dan meja, maka setelah beberapa contoh, program tersebut harus dapat memilah- milah objek ke dalam klasifikasi yang cocok. Kesulitan dari supervised learning adalah kita tidak dapat membuat klasifikasi yang benar. Dapat dimungkinkan program akan salah dalam mengklasifikasi sebuah objek setelah dilatih. Oleh karena itu, selain menggunakan training set kita juga memberikan test set. Dari situ kita akan mengukur persentase keberhasilannya. Semakin tinggi berarti semakin baik program tersebut. Persentase tersebut dapat ditingkatkan dengan diketahuinya temporal dependence dari sebuah data. Misalnya diketahui bahwa 70% mahasiswa dari jurusan Teknik Informatika adalah laki- laki dan 80% mahasiswa dari jurusan Sastra adalah wanita. Maka program tersebut akan dapat mengklasifikasi dengan lebih baik.
berikut cth gambarnya 😀
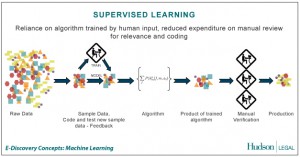
– Unsupervised learning : merupakan pembelajan yang tidak terawasi dimana tidak memerlukan target output. Pada metode ini tidak dapat ditentukan hasil seperti apa yang diharapkan selama proses pembelajaran, nilai bobot yang disusun dalam proses range tertentu tergantung pada nilai output yang diberikan. Tujuan metode uinsupervised learning ini agar kita dapat mengelompokkan unit-unit yang hampir sama dalam satu area tertentu. Pembelajaran ini biasanya sangat cocok untuk klasifikasi pola.
Atau
Teknik ini menggunakan prosedur yang berusaha untuk mencari partisi dari sebuah pola. Unsupervised learning mempelajari bagaimana sebuah sistem dapat belajar untuk merepresentasikan pola input dalam cara yang menggambarkan struktur statistikal dari keseluruhan pola input. Berbeda dari supervised learning, unsupervised learning tidak memiliki target output yang eksplisit atau tidak ada pengklasifikasian input.
Dalam machine learning, teknik unsupervised sangat penting. Hal ini dikarenakan cara bekerjanya mirip dengan cara bekerja otak manusia. Dalam melakukan pembelajaran, tidak ada informasi dari contoh yang tersedia. Oleh karena itu, unsupervised learning menjadi esensial.
Contoh :
– Contoh algoritma jaringan saraf tiruan yang menggunakan metode unsupervised ini adalah competitive, hebbian, kohonen, LVQ(Learning Vector Quantization), neocognitron.
– Competitive learning, di mana neuron-neuron saling bersaing untuk menjadi pemenang.
– Ilustrasi yang mudah misalkan hubungan antara murid dan dosen pada contoh yang sebelumnya. Ketika si murid menjumpai masalah, ia harus dapat menjawab masalah tersebut dengan sendirinya. Semakin banyak ia berusaha menjawab sendiri, ia akan semakin pandai dalam menemukan rule yang dapat digunakan untuk memecahkan permasalahan di kemudian hari.
berikut contoh gambarny 😀
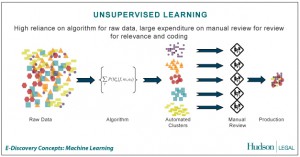
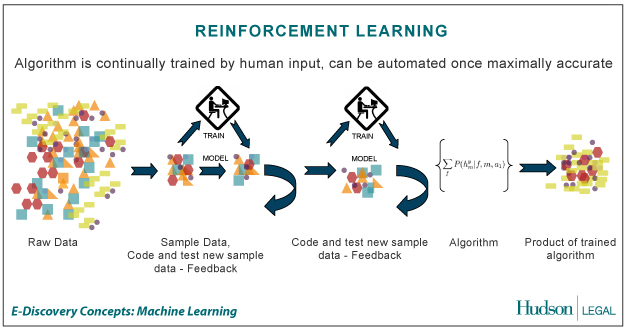
– Reinforcement learning : Konsep dasar reinforcement learning diambil dari suatu teori dalam ilmu psikologi yang disebut dengan reinforcement theory. Reinforcement theory ini merupakan suatu pendekatan psikologi yang sangat penting bagi manusia. Teori ini menjelaskan bagaimana seseorang itu dapat menentukan, memilih dan mengambil keputusan dalam dinamika kehidupan. Kelebihan lain dari teori ini dapat digunakan pada berbagai macam situasi yang seringkali dihadapi manusia (Bertsekas, 1996 : 2).
Menurut Masayu Leylia (2003:2) reinforcement learning merupakan pembelajaran hasil interaksi dengan lingkungan, sehingga dapat diperoleh maximal cummulative reward saat goal tercapai. Hal senada diungkapkan oleh Ali Ridho Barakbah (2007:3-6) reinforcement learning adalah salah satu paradigma baru di dalam learning theory. Reinforcement learning dibangun dari proses mapping (pemetaan) dari situasi yang ada di environment (states) ke bentuk aksi (behavior) agar dapat memaksimalkan reward. Reinforcement learning secara umum terdiri dari 4 komponen dasar, yaitu: (a) policy : kebijaksanaan, (b) reward function, (c) value function, dan (d) model of environment.
Contoh :
– Contoh yang realistis, AI dalam permainan, seperti catur atau monopoli. Kalau agen itu pintar dan menang, di dapat hadiah, atau sekedar ucapan ‘Selamat Anda Menang’ dan kalau kalah tentu saja ucapan yang berlawanan.
– Contoh yang paling mudah yang bisa saya gambarkan disini adalah bagaimana sikap yang diambil oleh seorang siswa di dalam kelas. Asumsikan bahw a sang guru sudah menjelaskan seperangkap aturan yang harus ditaati oleh siswa di dalam kelas. Suatu ketika, seorang siswa berteriak di dalam kelas. Maka sang guru langsung memberikan hukuman kepada siswa tersebut. Dari hukuman itu, siswa tadi akan merubah sikapnya untuk tidak berteriak lagi. Juga demikian, kepada siswa yang tekun mengikuti pelajaran di dalam kelas, maka sang guru memberikan kepada mereka semacam hadiah atau penghargaan. Jika sistem ini berjalan dalam jangka waktu tertentu, maka keadaan siswa tadi pasti akan konvergen untuk mengambil sikap yang baik di dalam kelas.
berikut contoh gambarny 😀
2. Apa yang dimaksud dengan Learning Decision Tree ?
– Secara singkat bahwa Decision Tree merupakan salah satu metode klasifikasi pada Text Mining. Klasifikasi adalah proses menemukan kumpulan pola atau fungsi-fungsi yang mendeskripsikan dan memisahkan kelas data satu dengan lainnya, untuk dapat digunakan untuk memprediksi data yang belum memiliki kelas data tertentu (Jianwei Han, 2001).
– Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu.
Contoh :
Beberapa Terms Examples (S), adalah training examples yang ditunjukkan oleh tabel di bawah ini:
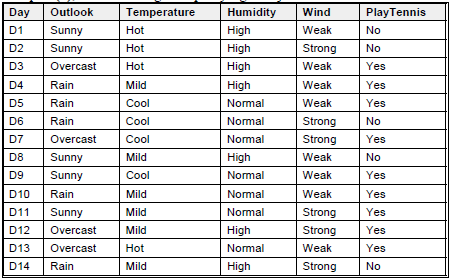
Target attribute adalah PlayTennis yang memiliki value yes atau no, selama 14 minggu pada setiap Sabtu pagi. Attribute adalah Outlook, Temperature, Hunidity, dan Wind.
Algoritma
PROCEDURE ID3(Examples, TargetAttribute, Attributes)5
Examples are the training examples. Target-attribute is the attribute whose value is to be
predicted by the tree. Attributes is a list of other attributes that may be tested by the
learned decision tree. Returns a decision tree that correctly classifies the given Examples.
• Create a Root node for the tree
• If all Examples are positive, Return the single-node tree Root, with label = +
• If all Examples are negative, Return the single-node tree Root, with label = –
• If Attributes is empty, Return the single-node tree Root, with label = most common
value of Target_attribute in Examples
• Otherwise Begin
• A <— the attribute from Attributes that best* classifies Examples
• The decision attribute for Root <— A
• For each possible value, vi, of A,
• Add a new tree branch below Root, corresponding to the test A = vi
• Let Examplesvi be the subset of Examples that have value vi for A
• If Examplesvi is empty
• Then below this new branch add a leaf node with label = most common
• value of Target_attribute in Examples
• Else below this new branch add the subtree
• Call ID3 (Examples, Target_attribute, Attributes – {A}))
• End
• Return Root
The best attribute is the one with highes information gain, as defined in Equation:
![]()
S adalah koleksi dari 14 contoh dengan 9 contoh positif dan 5 contoh negatif, ditulis dengan notasi [9+,5-]. Entropy dari S adalah:
![]()
Entropy([9+,5-]) = – (9/14)log2(9/14) – (5/14)log2(5/14)
= 0.94029
Catatan:
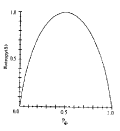
• Entropy(S)=0, jika semua contoh pada S berada dalam kelas yang sama.
• Entropy(S)=1, jika jumlah contoh positif dan jumlah contoh negatif dalam S adalah sama.
• 0<Entropy(S)<1, jika jumlah contoh positif dan negatif dalam S tidak sama.
Gain(S,A) adalah Information Gain dari sebuah attribute A pada koleksi contoh S.6
Values(Wind) = Weak, Strong
SWeak = [6+,2-]
SStrong = [3+,3-]
Gain(S,Wind) = Entropy(S) – (8/14)Entropy(SWeak) – (6/14)Entropy(SStrong)
= 0.94029 – (8/14)0.81128 – (6/14)1.0000
= 0.04813
Values(Humidity) = High, Normal
SHigh = [3+,4-]
SNormal = [6+,1-]
Gain(S,Humidity) = Entropy(S) – (7/14)Entropy(SHigh) – (7/14)Entropy(SNormal)
= 0.94029 – (7/14)0.98523 – (7/14)0.59167
= 0.15184
Values(Temperature) = Hot, Mild, Cool
SHot = [2+,2-]
SMild = [4+,2-]
SCool = [3+,1-]
Gain(S,Temperature) = Entropy(S) – (4/14)Entropy(SHot) – (6/14)Entropy(SMild)- (4/14)Entropy(SCool)
= 0.94029 – (4/14)1.00000 – (6/14)0.91830 – (4/14)0.81128
= 0.02922
Values(Outlook) = Sunny, Overcast, Rain
SSunny = [2+,3-]
SOvercast = [4+,0-]
SRain = [3+,2-]
Gain(S,Outlook) = Entropy(S) – (5/14)Entropy(SSunny) – (4/14)Entropy(SOvercast)
-(5/14)Entropy(SRain)
= 0.94029 – (5/14)0.97075 – (4/14)1.000000 – (5/14)0.97075
= 0.24675
Jadi, information gain untuk 4 atribut yang ada adalah:
Gain(S,Wind) = 0.04813
Gain(S,Humidity) = 0.15184
Gain(S,Temperature) = 0.02922
Gain(S,Outlook) = 0.24675
Dari perhitungan tersebut, tampak bahwa attribute Outlook akan menyediakan prediksi terbaik untuk target attribute PlayTennis.
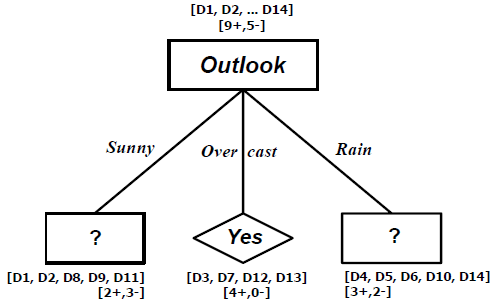
Untuk branch node Outlook=Sunny,
SSunny = [D1, D2, D8, D9, D11]
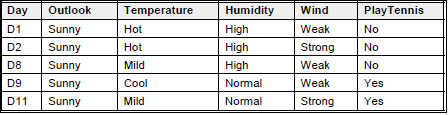
Values(Temperature) = Hot, Mild, Cool
SHot = [0+,2-]
SMild = [1+,1-]
SCool = [1+,0-]
Gain(SSunny, Temperature) = Entropy(SSunny) – (2/5)Entropy(SHot) – (2/5)Entropy(SMild)
– (1/5)Entropy(SCold)
= 0.97075 – (2/5)0.00000 – (2/5)1.00000 – (1/5)0.00000
= 0.57075
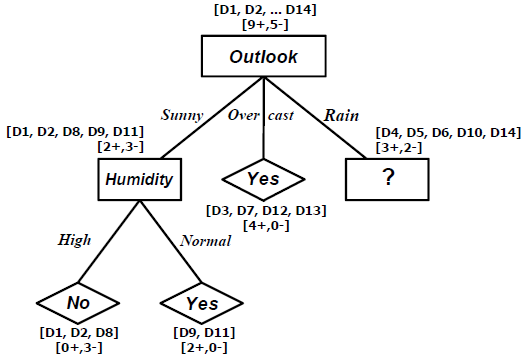
Values(Humidity) = High, Normal
SHigh = [0+,3-]
SNormal = [2+,0-]
Gain(SSunny, Humidity) = Entropy(SSunny) – (3/5)Entropy(SHigh) – (2/5)Entropy(SNormal)
= 0.97075 – (3/5)0.00000 – (2/5)1.00000
= 0.97075
Values(Wind) = Weak, Strong
SWeak = [1+,2-]
SStrong = [1+,1-]
Gain(SSunny, Wind) = Entropy(SSunny) – (3/5)Entropy(SWeak) – (2/5)Entropy(SStrong)
= 0.97075 – (3/5)0.91830 – (2/5)1.00000
= 0.01997
Untuk branch node Outlook=Rain,
SRain = [D4, D5, D6, D10, D14]
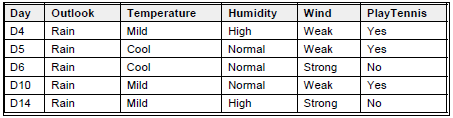
Values(Temperature) = Mild, Cool {Tidak ada lagi temperature=hot saat ini}
SMild = [2+,1-]
SCool = [1+,1-]
Gain(SRain, Temperature) = Entropy(SRain) – (3/5)Entropy(SMild) – (2/5)Entropy(SCold)
= 0.97075 – (3/5)0.91830 – (2/5)1.00000
= 0.01997
Values(Humidity) = High, Normal
SHigh = [1+,1-]
SNormal = [2+,1-]
Gain(SRain, Humidity) = Entropy(SRain) – (2/5)Entropy(SHigh) – (3/5)Entropy(SNormal)
= 0.97075 – (2/5)1.00000 – (3/5)0.91830
= 0.01997
Values(Wind) = Weak, Strong
SWeak = [3+,0-]
SStrong = [0+,2-]
Gain(SRain, Wind) = Entropy(SRain) – (3/5)Entropy(SWeak) – (2/5)Entropy(SStrong)
= 0.97075 – (3/5)0.00000 – (2/5)0.00000
= 0.97075
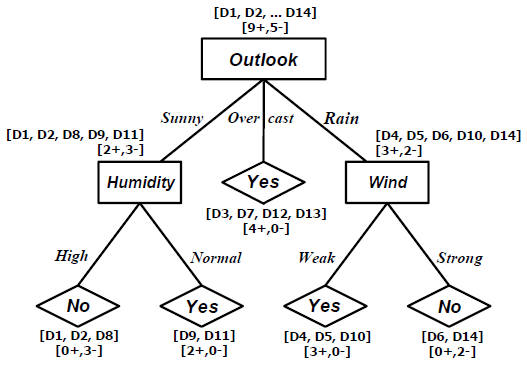
Rule-Rule yang telah Dipelajari, dengan memperhatikan decision tree yang dihasilkan adalah :
• IF Outlook = Sunny AND Humidity = High THEN PlayTennis = No
• IF Outlook = Sunny AND Humidity = Normal THEN PlayTennis = Yes
• IF Outlook = Overcast THEN PlayTennis = Yes
• IF Outlook = Rain AND Wind = Strong THEN PlayTennis = No
• IF Outlook = Rain AND Wind = Weak THEN PlayTennis = Yes